
Розвиток моделей зору зазнав значних змін із появою великих мовних моделей (LLM). Традиційно візуальні моделі працювали у фіксованих рамках, але інтеграція з LLM відкрила нові горизонти для попереднього навчання, дозволяючи створювати більш адаптивні й універсальні системи. Ця трансформація спрямувала дослідників на розробку підходів, які відповідають потребам мультимодальних застосувань.
Про це інформує Syncedreview.
Дослідницька група Apple презентувала AIMV2 у новій статті Multimodal Autoregressive Pre-training of Large Vision Encoders. Ця інновація демонструє використання мультимодального авторегресійного підходу для навчання візуальних кодерів. На відміну від традиційних методів, AIMV2 прогнозує як зображення, так і текстові маркери в єдиній послідовності, відкриваючи нові можливості в таких завданнях, як розпізнавання зображень, візуальне заземлення й мультимодальне розуміння.
Основні інновації AIMV2
Ключовою особливістю AIMV2 є інтеграція унімодального авторегресійного підходу в мультимодальне середовище. Розглядаючи патчі зображень і текстові маркери як єдину послідовність, модель покращує здатність розуміти взаємозв’язки між зображенням і текстом.
Процес попереднього навчання AIMV2 включає:
- Мультимодальний декодер: модель прогнозує зображення й текстові маркери поетапно, використовуючи причинно-наслідковий підхід.
- Ефективність навчання: AIMV2 потребує менших обчислювальних ресурсів, оскільки усуває складності, пов’язані з великими партіями даних.
- Узгодженість із LLM: архітектура інтегрується з мовними моделями, що забезпечує зручність і гнучкість у мультимодальних програмах.
Серед ключових архітектурних змін:
- Обмежена самоувага: використання префіксної маски уваги для забезпечення двонаправленого прогнозування без додаткових налаштувань.
- Стабілізація навчання: впровадження функції SwiGLU як активації та заміна нормалізації на RMSNorm для підвищення стабільності.
- Уніфікований декодер: єдина архітектура для прогнозування як тексту, так і зображень, що підсилює мультимодальні можливості.
Результати й переваги AIMV2
Модель AIMV2-3B демонструє видатні результати, досягаючи 89,5% точності на ImageNet-1k із замороженим стовбуром. Вона також перевершує сучасні контрастивні моделі, такі як CLIP і SigLIP, у тестах на мультимодальне розуміння зображень.
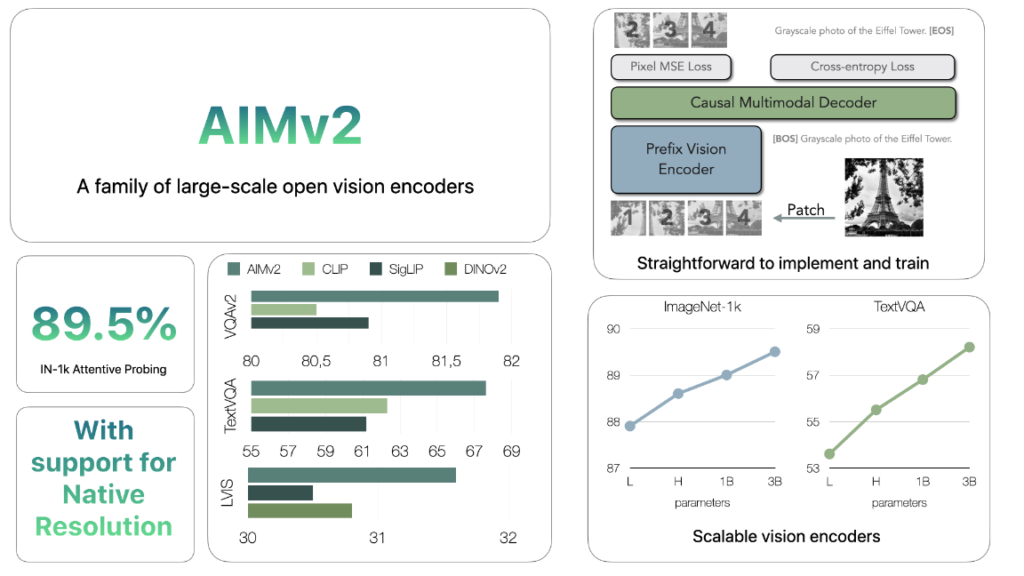
Однією з основних причин цього є здатність AIMV2 максимально використовувати навчальні сигнали від усіх вхідних даних, забезпечуючи більш ефективне навчання навіть із невеликими обсягами даних.
Майбутнє мультимодальних систем
AIMV2 представляє значний крок уперед у розвитку моделей зору. Завдяки поєднанню прогнозування зображень і тексту в одній авторегресійній системі модель забезпечує високу продуктивність у багатьох завданнях.
Спрощений процес навчання та вдосконалення, такі як SwiGLU і RMSNorm, роблять AIMV2 масштабованим і адаптивним рішенням. Ця розробка може стати основою для створення більш ефективних і універсальних мультимодальних систем навчання в майбутньому.
